Sending Large Amounts of Email Safely
Sending large amounts of email isn't as straightforward as you might think. Over the past couple of years I've learned many lessons in this realm of technology from how to build systems to handle this to managing reputation properly.


Part of my work at Fullscreen Direct is building and managing systems that allow for large email campaign sending capabilities. This was part of our core value proposition early on when we were still StageBloc: not only can we help you centralize your fan content, we also let you take actions on it such as email marketing.
Back then I was quite naive and didn't realize how much work something as seemingly simple as "sending lots of email" really was. Outside of building systems to efficiently and robustly handle the sends, managing the reputation of our IP addresses quickly became something we'd need to spend a lot of time addressing.
Our Functionality
To start, I'd like to frame the types of email we are dealing with. We currently handle two main types of email sending. The first is our basic transactional type email. This is simply messages for when fans sign up, order something from one of the store on our platform, need to reset their password, etc. There isn't much complexity in handling this.
The second type is where much of our complexity comes in. These are large, campaign based marketing emails written by our customers. For instance, on a given day we may have one customer send an email announcing a tour to 600k fans and another customer send one about a sale in their store to 300k of their fans. Both of these may be timely messages meaning we need to send close to one million emails within an a couple of hours.
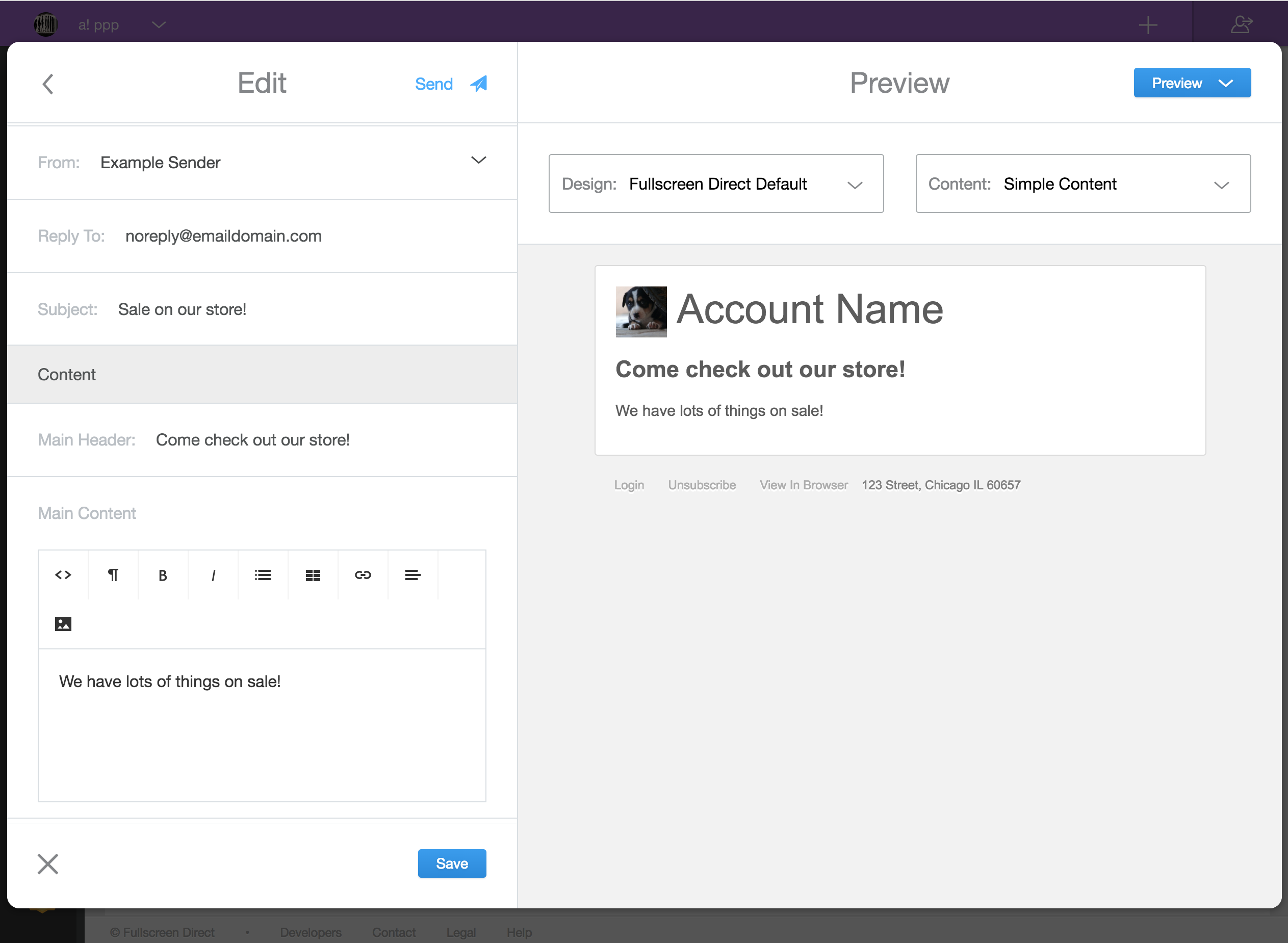
For additional context our current interface for building these campaigns can be seen above. Customers are able to essentially customize anything about these emails including filtering which of their fans it goes to. This is where managing reputation becomes difficult as we aren't in control of what is contained within these messages.
Our Journey
Around 2010 we first started out sending email through Dyn. We quickly realized that email is sort of an afterthought for Dyn as opposed to one of their core offerings. We weren't very happy with the way it was going.
Since the rest of our infrastructure was on AWS we decided to try Simple Email Service (SES). Step one to this migration was creating our own open and click tracking since previously Dyn had been doing that for us. These again seem simple on the surface but have their own nuances.
For instance, open tracking is typically handled via an invisible pixel in the image that, when loaded, simply tells your server someone has "opened" this email. If a bunch of customers receive and open this email at the same time, this can also lead to a spike in "traffic" against your servers that you need to be careful about.
Over time our sending via SES had been going pretty well. However, we started to run in to our more interesting problems as we grew. One day seemingly out of nowhere we received an email about our sending ability being "on probation". We were told that if we didn't resolve the problem within a particular time frame we could then even be suspended from sending email through SES all together. This obviously would not have been good for our business.
Over the next couple of quarters we ended up on probation for a couple of reasons including:
- The bounce rate of our sends was too high
- A spam trap email address had received an email from us
- An Email Service Provider (ESP) had received a high amount of complaints from mail originating from us
Each time we were able to make appropriate changes to our system to address the issue. However, each time this happened was another large lesson learned in sending email safely. I'll get to those learnings below.
Nowadays we are still sending mail through SES. However, in an effort to make our sending ability less reliant on one provider we also send mail through SendGrid. SendGrid gives us more flexibility over how we manage and split our reputation across IP addresses which is extremely valuable.
Our Infrastructure
The key piece of our infrastructure for sending email is our message queueing service. Historically that's been RabbitMQ though recently we've been working on migrating to AmazonMQ.
We have two main email sending queues, a high priority one and a low priority one. The high priority queue is what most of our transactional mail goes through to ensure it's delivered in a timely manner. The low priority queue is where campaign email gets routed through here. In this queue a backlog of mail is more acceptable due to the volume being sent. The main point of these two separate queues is we don't want a tour announcement email holding up customers receiving their order receipts or other email.
When a campaign email is triggered to be sent, a message is fired containing the ID of that campaign. An emailer-campaign queue picks this up and starts to iterate through the users who should receive this email. For each of these users, a second message is fired that is picked up by a separate email-message-building queue. This message mainly contains the ID of the user this mail is going to and which campaign it is for.
The image below shows what may happen when one of these large email is kicked off. A bunch of queue messages are created and begin to be consumed.
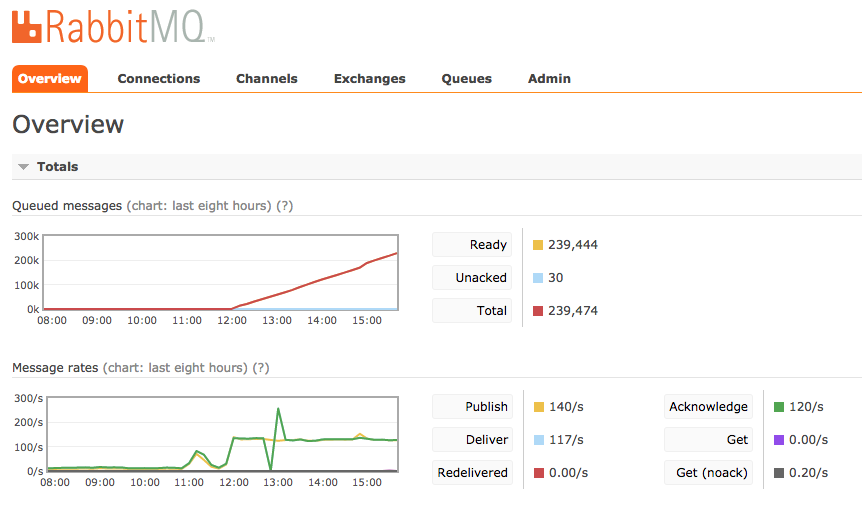
The trick here is that the email-campaign queue needs to iterate through potentially hundreds of thousands of users. If some exception occurs or the consumer process is restarted for any reason we need to ensure we don't start over and send duplicate mail to everyone. To handle this we created "stateful consumers". All this really means is that they ocassionally save their state to the database so they can resume where they left off if they are restarted. In the case of email sending this is mostly just the offset of the users it has already processed.
Once the email-message-building queue picks up a message it takes care of loading all of the appropriate data to build the email. It then combines this data with the template of the email to construct the actual HTML email message. This queue then fires a third message that our email-low queue consumer handles. This is the low priority email queue described earlier that actually sends the email. In our case this consumer essentially just receives the contents of the email and makes a call to the SES or SendGrid API to send it.
The reason the building and sending queues are separate is because we can then scale them seperately. SES currently allows us to send emails at 300 a second. This means we should be building email at a rate that gets us as close to that sending amount as we can so that the email goes out as quickly as possible. We essentially tweak the ratio of email-message-building queue consumers to email-low queue consumers to achieve this.
Key Learnings
There are a vast amount of learnings I've had over the years of sending large amounts of email. Many of the key learnings revolve around managing reputation so that ESPs trust your mail is not of a spammy nature.
Have a way of tracking / removing bounced email addresses
This seems extremely obvious to anyone who has dealt with email sending before, but if you are new to the industry then it may not be. Sending email more than once to any address that hard bounces is a large indicator to ESPs that you aren't properly keeping your lists up to date with valid addresses. Many email sending providers have a way of notifiying you of bounced mail which makes this pretty simple to do. For instance, SendGrid uses a webhook for this while SES pushes them to an SQS queue you can then consume them from.
Send mail to questionable addresses over time
In our industry we deal with many customers who have lists they've built up over time but haven't properly managed. To them, quantity is better than quality even tho when sending email quality and engaged recipients is really all that matters.
As a way to help serve our customers but also secure the reputation of our email sending we built a system that identifies email addresses we deem "questionable". This mostly just means we haven't sent to them before. If these addresses are part of a campaign we will send to them slowly over time due to their risk. This way any bounce rates or complaint rates remain low relative to the overall sending size during any given time frame.
Log everything
When issues arise with your reputation ESPs often don't give you much information. This is to ensure it's not easy for you to game the controls they have in place. Therefore having the appropriate logging in place on your end is extremely valuable. In our case we store a large amount of our sending information, bounce tracking, etc in ElasticSearch. This way if issues arise in particular time frames we can easily query it to help find the cause of any issues.
Partition larger / riskier customers to their own IPs
A large part of email reputation is based on the IP address the mail is originating from. In our case we have some customers that send mail more deemed to be annoying or spammy than others. For these instances we can put mail sent by them on it's own IP address. Then if any issues arise with reputation it at least is limited to one IP address and can be managed accordingly.