SmushIt - A Golang AWS Lambda Archiving Function
I've come across many times where I've needed to take some files at a group of URLs, download them, zip them up, and send them to someone. Unfortunately once the final archive gets to a certain size it becomes difficult to easily share (especially via email). So I wrote SmushIt.


I've come across many times where I've needed to take some files at a group of URLs, download them, zip them up, and send them to someone. Unfortunately once the final archive gets to a certain size it becomes difficult to easily share (especially via email). Services like WeTransfer help, but (puts on tinfoil hat) who knows what happens with your data once it's given to someone else. I also wanted a more automated way of being able to do this that could then be used as a micro-service of sorts in other projects. One good example of this would be letting your users export any photos they have uploaded to your service.
Given this need I figured it'd be a good excuse to explore AWS Lambda and API Gateway to create a solution. The result of this exploration is SmushIt, a Golang Lambda function that does the following:
- Takes an array of URLs
- Downloads the files from the URLs concurrently
- Zips them up
- Responds with a URL to download them via S3
How It Works
The Golang code in the GitHub repo consists of the main logic needed to make this work. To actually run the code I configured an endpoint in API Gateway to trigger the Lambda function. The request looks like this:
{
"filename": "randomImages",
"urls": [
"https://placeimg.com/640/480/any?1",
"https://placeimg.com/640/480/any?2",
"https://placeimg.com/640/480/any?3"
]
}
Once triggered, the code will begin concurrently downloading any data at the urls provided. The code hashes the URL to use as the filename which means only one file will be included per unique URL (hence the ?1, etc in the URLs above). Another caveat in the code is that there is a mimeTypes array of file formats allowed in the code. My use case was specifically for media, so this is there mostly as a sanity check that requests aren't providing URLs to executables or other random files.
Once the files are all downloaded the code will archive them in to a single zip file and upload this file to S3 using the filename provided. This means each unique request of files should be given a unique filename to avoid accidental overwriting. The upload path for S3 is prefixed with a hashed version of the API key in the code. This is to support numerous different clients all re-using the same function having their files namespaced in S3.
The response will look like this:
{
"downloadUrl": "https://smushit.s3.amazonaws.com/f450ebd4a05c18fab8a06761e40f4af8/randomImages.zip?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAIDEGKYGDCA%2F20180506%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20180506T180200Z&X-Amz-Expires=86400&X-Amz-SignedHeaders=host&X-Amz-Signature=292f4d33993e1f875b2b4d9c3b8e8c05976e09f0e8d4",
"message": "Successfully uploaded randomImages.zip"
}
Due to the oneDayFromNow := time.Now().AddDate(0, 0, 1) line in the code this URL will only be valid for 24 hours. I've also configured my S3 bucket to automatically expire the files after 24 hours since these downloads are meant to be ephemeral. If the file is needed again it can just be regenerated via another call to the API.
The name of the download will match whatever was provided via the filename parameter.
Note that this isn't really meant to be used when realtime responses are needed. Downloading the files and re-uploading them takes time. This may be more useful to run in the background then email the link to a user or something like that.
AWS Lambda
The first step was creating a Lambda function to do the bulk of the logic. I chose Golang because I've been wanting to learn more about Go and I knew it was good at handling concurrency.
The initial creation of Lambda functions is pretty straightforward through the AWS console. You essentially just choose a runtime and name then end up with something like this screenshot.
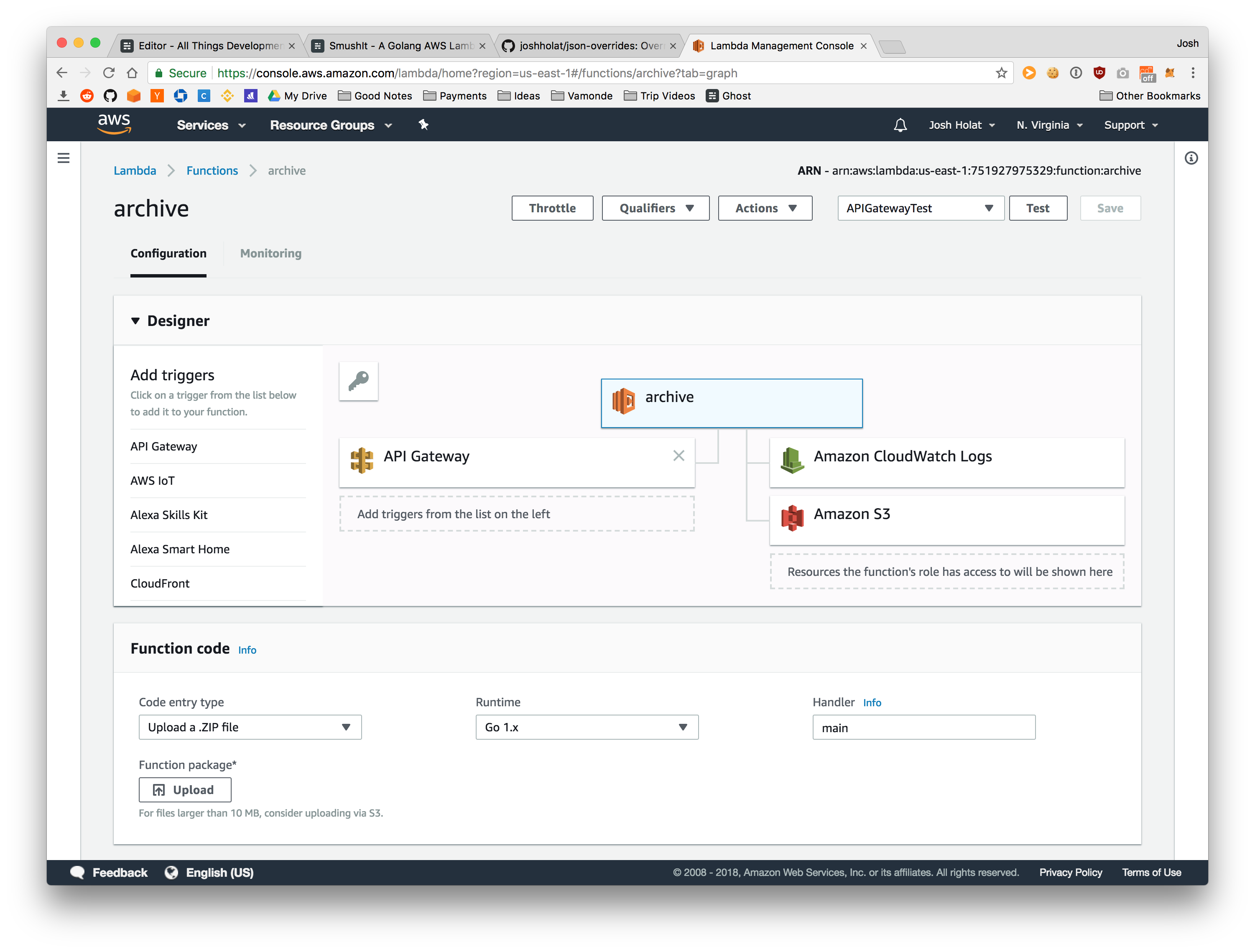
After you initially create your Lambda function, updating the code for it is as quick as running the AWS CLI command below. You are also able to upload the zip file in the AWS console, but I prefer the command line interface. For Golang specifically you also need to build your code first.
GOOS=linux GOARCH=amd64 go build -o main main.go
zip main.zip main
aws lambda update-function-code --function-name archive --zip-file fileb://main.zip
One important thing to note is that Lambda is charged via execution time. Execution time is currently limited to 300 seconds per invocation. Therefore SmushIt won't necessarily work if you need to download very large files as pulling those down then re-uploading a zip file of them all could easily take longer 5 minutes.
API Gateway
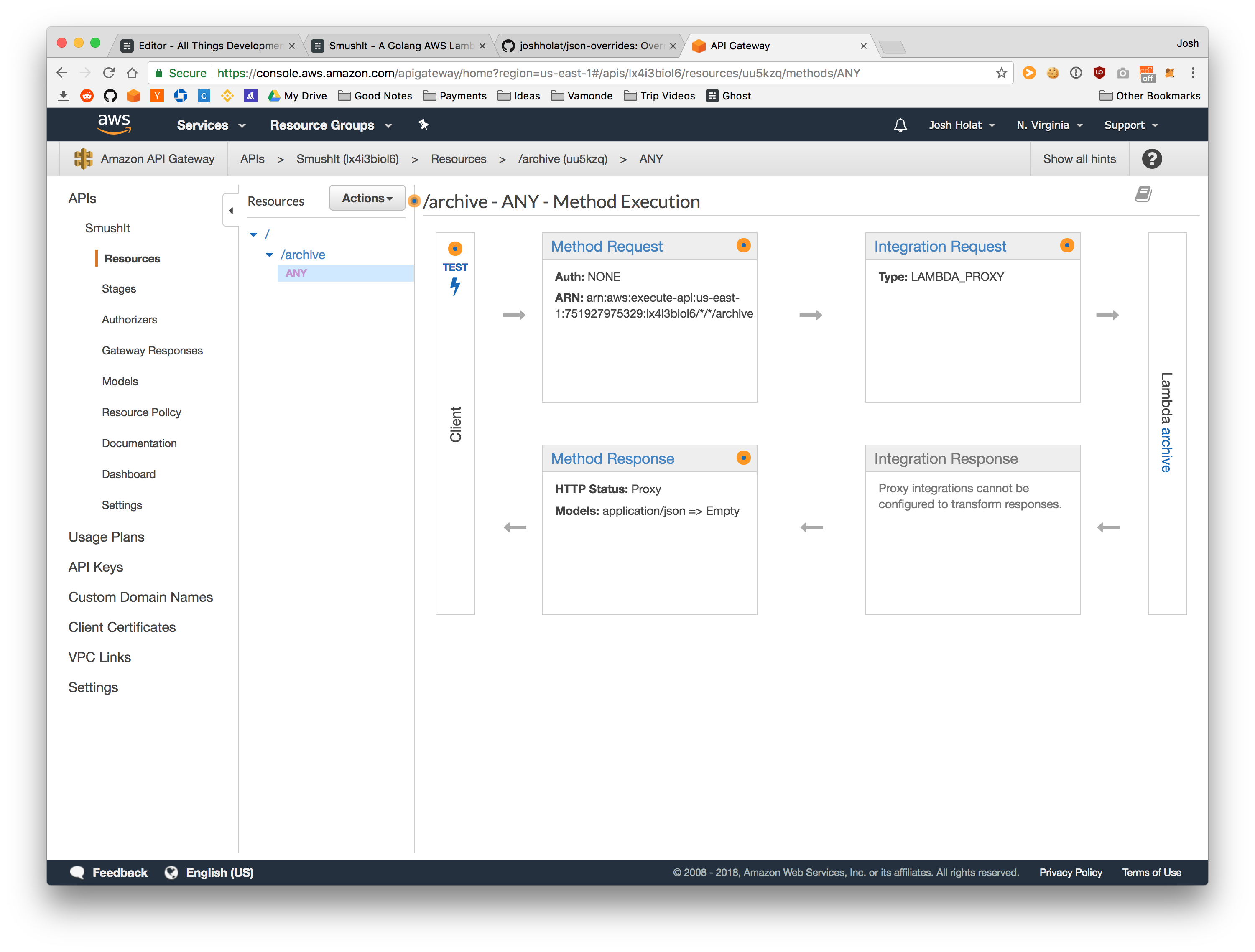
Once I had the Lambda function created, I needed an easy way to trigger it. Since API Gateway is another AWS property it handles this really well. As seen in the screenshot above you need to add an API Gateway trigger for your function. Once you do this AWS takes care of sending requests to your API endpoint to your Lambda function for you.
The first time you use API Gateway it can be pretty confusing. However, once you get over the initial learning curve it becomes quite powerful pretty quickly. For example, it has a built in way of handling authentication and rate limiting via API keys which saves a lot of time.
Local Development
The AWS SAM Local tool is used to test serverless functions locally. After installing it you start it via sam local start-api which will use the template.yml file to define which endpoints are available. Note that you'll need to change the role ARN from the one in the repo.
Then you can use the Postman collection in the repo to make requests against the function.
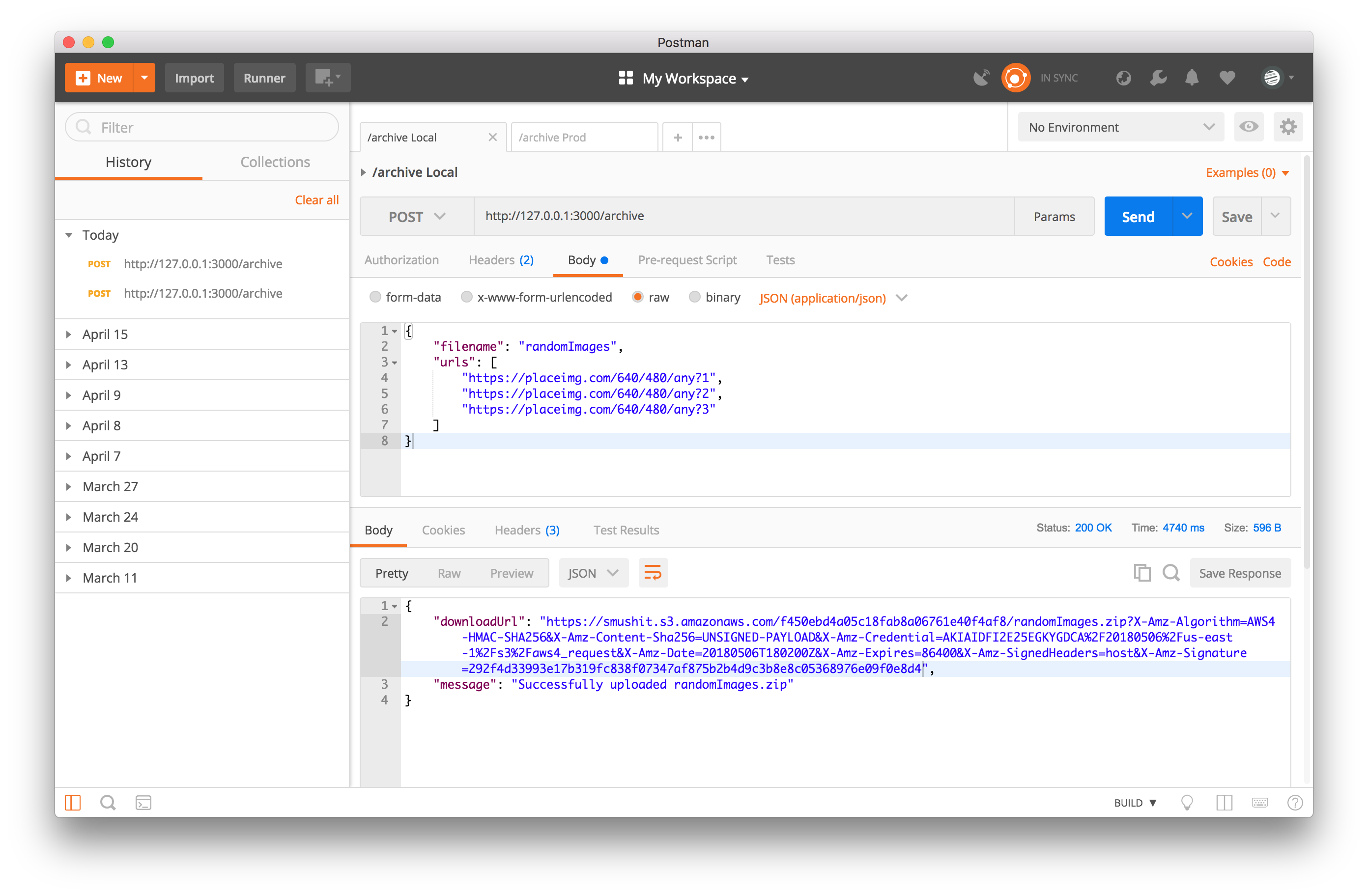
The great thing about this AWS tool is it shows you the output of what resources you are using that you would be billed for on AWS itself. For instance, here's the output of the request data from above.
2018/05/06 11:01:59 Invoking main (go1.x)
2018/05/06 11:01:59 Mounting /Users/joshholat/Documents/Code/SmushIt as /var/task:ro inside runtime container
START RequestId: d2eb5cb9-1d09-1b66-a1e2-99dc990e69b5 Version: $LATEST
2018/05/06 18:01:56 Request data: {
"filename": "randomImages",
"urls": [
"https://placeimg.com/640/480/any?1",
"https://placeimg.com/640/480/any?2",
"https://placeimg.com/640/480/any?3"
]
}
2018/05/06 18:01:56 API Key: REDACTED
2018/05/06 18:01:56 Parsed request data: &{randomImages [https://placeimg.com/640/480/any?1 https://placeimg.com/640/480/any?2 https://placeimg.com/640/480/any?3]}
Downloading https://placeimg.com/640/480/any?3 to /tmp/5e94187d83f1ddf4b982e4bab5c13ab3
Downloading https://placeimg.com/640/480/any?2 to /tmp/395fdf98fe19641901af43a2c8524330
Downloading https://placeimg.com/640/480/any?1 to /tmp/2067c1f6bc9fc3fc2e6c7d2e515d9769
201583 bytes downloaded
201132 bytes downloaded
183159 bytes downloaded
2018/05/06 18:01:57 3 files to archive: [/tmp/5e94187d83f1ddf4b982e4bab5c13ab3.jpeg /tmp/395fdf98fe19641901af43a2c8524330.jpeg /tmp/2067c1f6bc9fc3fc2e6c7d2e515d9769.jpeg]
2018/05/06 18:01:57 Uploading file /tmp/download.zip as f450ebd4a05c18fab8a06761e40f4af8/randomImages.zip
END RequestId: d2eb5cb9-1d09-1b66-a1e2-99dc990e69b5
REPORT RequestId: d2eb5cb9-1d09-1b66-a1e2-99dc990e69b5 Duration: 3455.87 ms Billed Duration: 3500 ms Memory Size: 128 MB Max Memory Used: 14 MB
Final Thoughts
Regarding the code repository specifically I'd like to eventually add various CloudFormation files to make the setup of the AWS Lambda and API Gateway pieces more automated and clear. An additional feature that may be nice to support is allowing the requestor to specify the name of the individual files within the archive as well.
In general serverless architecture is one of those trendy topics in development right now. It can be very powerful, but I don't think it should be seen as a way to solve any and all problems you have. I chose to use it here mostly as an experiment. However, it also fits the use case decently well since all of the data is ephemeral and responses aren't expected to be instant.
Hopefully you find this useful or at least a good starting point for you own archiving functionality!